
Page 9 - No30
P. 9
TANULÁS, MODELLEZÉS, MINTAFELISMERÉS
ÉLETTANI ÉS ORVOSI NOBEL-DÍJ 2024
csomópontjainak aktivitásához. A j. a tanítás vagy másnéven a tréning vezérli, A GRADIENS
csomópont a kimeneti jelét meghatározó amely a neurális hálózatok tanulásának CSÖKKENTÉSÉNEK
j
paraméterek p a w súlyok és a b torzítás. alapvető algoritmusa. Ennek során a ALGORITMUSA
j
i
α
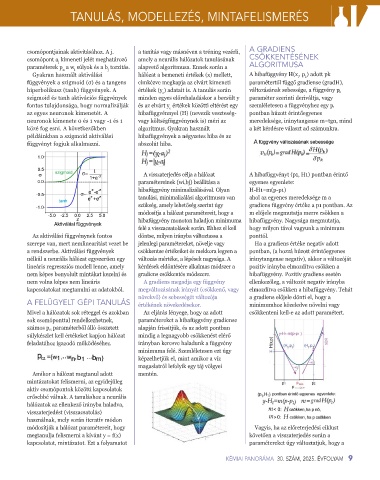
Gyakran használt aktiválási hálózat a bemeneti értékek (x) mellett, A hibafüggvény H(x , p ) adott pk
k
i
függvények a szigmoid (σ) és a tangens címkézve megkapja az elvárt kimeneti paramétertől függő gradiense (gradH),
hiperbolikusz (tanh) függvények. A értékek (y ) adatait is. A tanulás során változásának sebessége, a függvény p k
c
szigmoid és tanh aktivációs függvények minden egyes előrehaladáskor a becsült y paraméter szerinti deriváltja, vagy
fontos tulajdonsága, hogy normalizálják és az elvárt y értékek közötti eltérést egy szemléletesen a függvényhez egy p 1
c
az egyes neuronok kimenetét. A hibafüggvénnyel (H) (nevezik veszteség- pontban húzott érintőegyenes
neuronok kimenete 0 és 1 vagy -1 és 1 vagy költségfüggvénynek is) méri az meredeksége, iránytangense m=tgα, mind
közé fog esni. A következőkben algoritmus. Gyakran használt a két kérdésre választ ad számunkra.
példáinkban a szigmoid aktiválási hibafüggvények a négyzetes hiba és az
függvényt fogjuk alkalmazni. abszolút hiba.
A visszaterjedés célja a hálózat A hibafüggvényt (p1, H1) pontban érintő
paramétereinek {wi,bj} beállítása a egyenes egyenlete:
hibafüggvény minimalizálásával. Olyan H-H1=m(p-p1)
tanulási, minimalizálási algoritmusra van ahol az egyenes meredeksége m a
szükség, amely lehetőség szerint úgy gradiens függvény értéke a p1 pontban. Az
módosítja a hálózat paramétereit, hogy a m előjele megmutatja merre csökken a
hibafüggvény monoton haladjon minimuma hibafüggvény. Nagysága megmutatja,
felé a visszacsatolások során. Ehhez el kell hogy milyen távol vagyunk a minimum
Az aktiválási függvénynek fontos döntse, milyen irányba változtassa a ponttól.
szerepe van, mert nemlinearitást vezet be jelenlegi paramétereket, növelje vagy Ha a gradiens értéke negatív adott
a rendszerbe. Aktiválási függvények csökkentse értékeiket és mekkora legyen a pontban, (a hozzá húzott érintőegyenes
nélkül a neurális hálózat egyszerűen egy változás mértéke, a lépések nagysága. A iránytangense negatív), akkor a változóját
lineáris regressziós modell lenne, amely kérdések eldöntésére alkalmas módszer a pozitív irányba elmozdítva csökken a
nem képes bonyolult mintákat kezelni és gradiens csökkentés módszere. hibafüggvény. Pozitív gradiens esetén
nem volna képes nem lineáris A gradiens megadja egy függvény ellenkezőleg, a változót negatív irányba
kapcsolatokat megtanulni az adatokból. megváltozásának irányát (csökkenő, vagy elmozdítva csökken a hibafüggvény. Tehát
növekvő) és sebességét változója a gradiens előjele dönti el, hogy a
A FELÜGYELT GÉPI TANULÁS értékének növekedésekor. minimumhoz közeledve növelni vagy
Mivel a hálózatok sok réteggel és azokban Az eljárás lényege, hogy az adott csökkenteni kell-e az adott paramétert.
sok csomóponttal rendelkezhetnek, paramétereket a hibafüggvény gradiense
számos p α paraméterből álló összetett alapján frissítjük, és az adott pontban
súlykészlet kell értékeket kapjon hálózat mindig a legnagyobb csökkenést elérő
feladatához igazodó működéséhez. irányban keresve haladunk a függvény
minimuma felé. Szemléletesen ezt úgy
képzelhetjük el, mint amikor a víz
magaslatról lefolyik egy táj völgyei
Amikor a hálózat megtanul adott mentén.
mintázatokat felismerni, az egyidejűleg
aktív csomópontok közötti kapcsolatok
erősebbé válnak. A tanuláshoz a neurális
hálózatok az ellenkező irányba haladva,
visszaterjedést (visszacsatolás)
használnak, mely során iteratív módon
módosítják a hálózat paramétereit, hogy Vagyis, ha az előreterjedési ciklust
megtanulja felismerni a kívánt y = f(x) követően a visszaterjedés során a
kapcsolatot, mintázatot. Ezt a folyamatot paramétereket úgy változtatjuk, hogy a
KÉMIAI PANORÁMA 30. SZÁM, 2025. ÉVFOLYAM 9